
Kimi K1.5
Laying the groundwork for solving the token crisis.

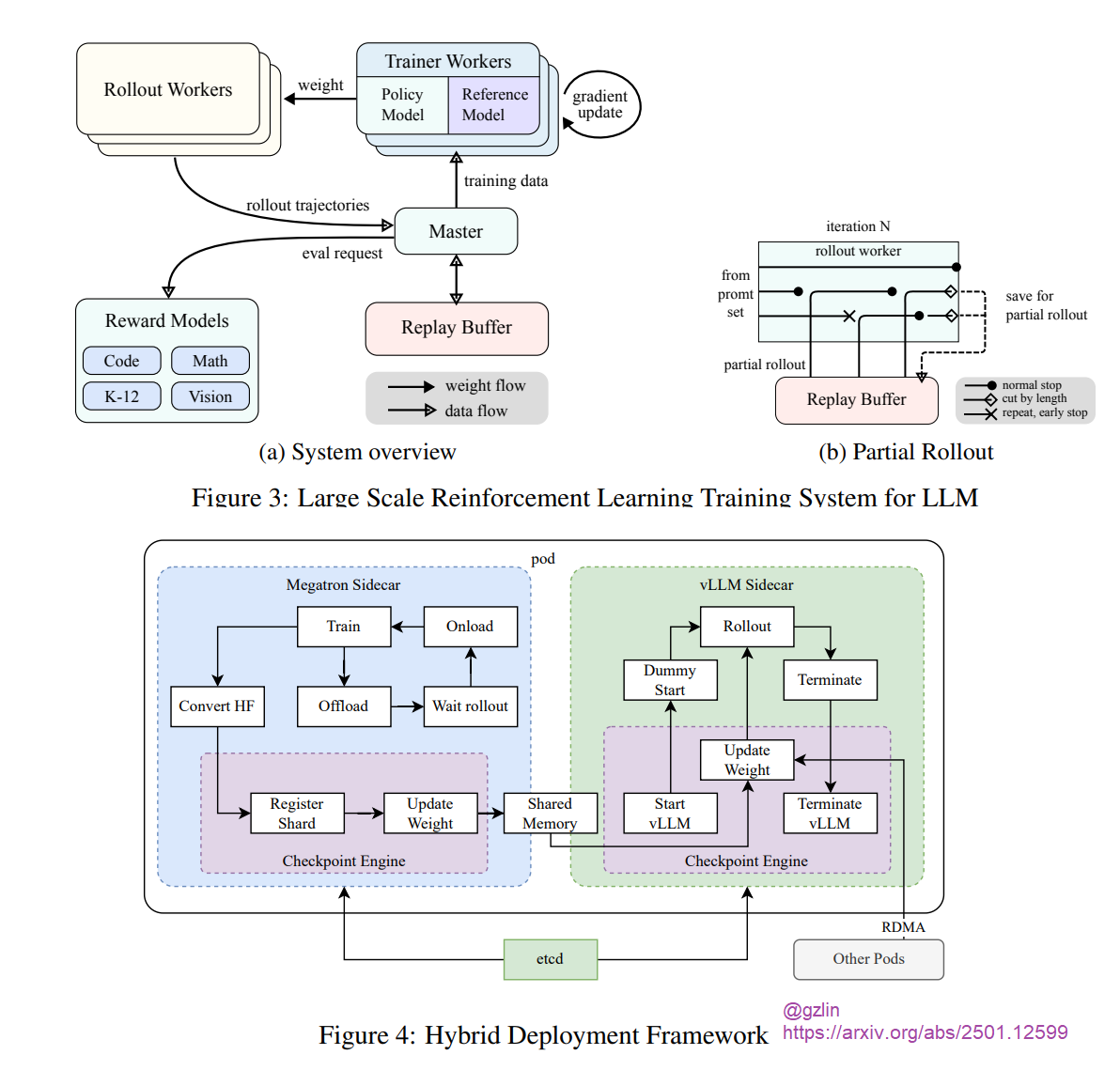
Given the exceptional performance of the Kimi K2, it's interesting to look back at the prior Kimi K1.5 model that served as a proof of concept. In their technical report detailing K1.5, the team emphasized both a multi-modality and RL approach to improve functionality and overcome the limitations associated with traditional pretraining methods that rely on static datasets.
One of the notable features of K1.5 is its use of RL techniques, which allow the model to dynamically explore and learn from rewards. This approach significantly broadens its training data and contributes to its strong performance on various benchmarks, achieving scores such as 77.5 on AIME and 96.2 on MATH 500.
The model also boasts an extended context window of up to 128k tokens, which enhances its ability to handle complex tasks. This is achieved through partial rollouts that facilitate the reuse of previous trajectories, thereby improving training efficiency.
K1.5 employs a straightforward training framework that emphasizes effective policy optimization and long-chain-of-thought (CoT) methods, steering clear of more complex techniques like Monte Carlo tree search.
In terms of training data, K1.5 is designed to work with both text and vision inputs, which enhances its reasoning capabilities across different modalities. This multi-modal approach allows the model to effectively address a wide range of tasks, from coding to mathematical reasoning.
The performance metrics indicate that K1.5 has surpassed existing models, particularly in short-CoT reasoning tasks, achieving improvements of up to 550% over competitors such as GPT-4o and Claude Sonnet 3.5.
The report also introduces innovative sampling strategies, including curriculum and prioritized sampling, which gradually increase task difficulty and help mitigate the model's weaknesses.
Additionally, a large-scale RL framework has been implemented to optimize resource utilization through a hybrid deployment strategy, ensuring efficient training and inference processes.
It's clear that the team executed on their potential areas for improvement such as enhancing credit assignment and minimizing overthinking in models, which boosted exploration capabilities without compromising performance.