
Automatic reinforcement learning rule extraction
The rise of mini online RL for LLMs

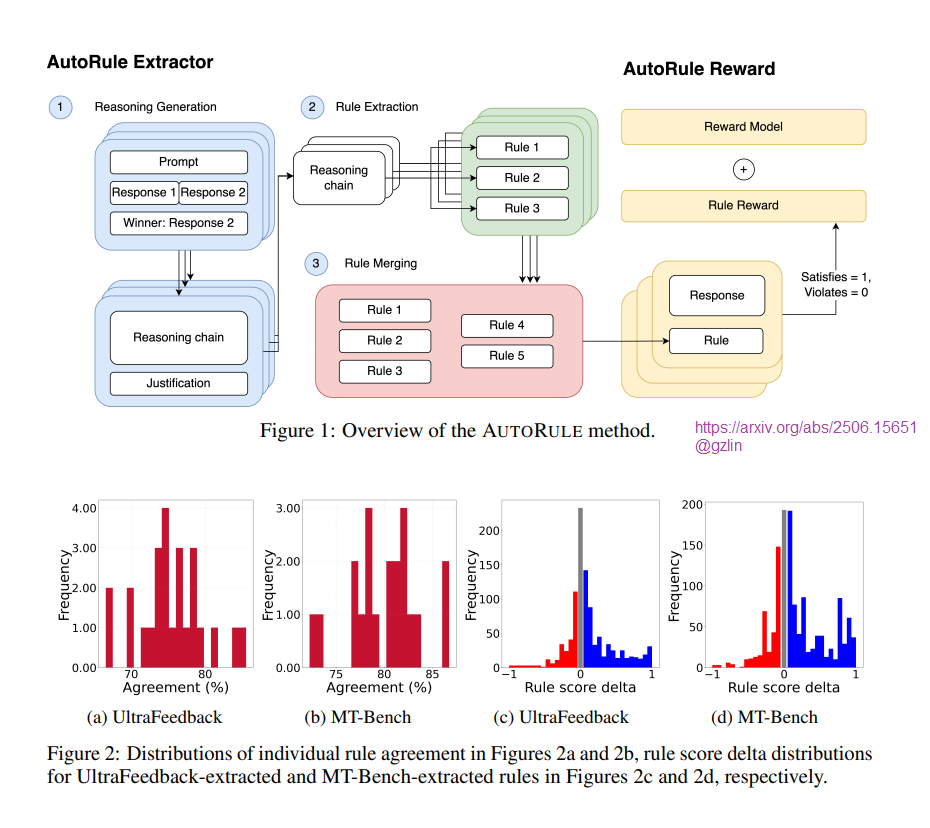
AUTORULE, from a team at CMU, is a framework designed to enhance reinforcement learning from human feedback (RLHF) by automating the extraction of rule-based rewards from user preferences. Traditional approaches often rely on manual rule crafting, which can lead to inefficiencies and inconsistencies. AUTORULE addresses these challenges through a three-stage automated process that leverages advanced reasoning models to interpret user feedback, identify potential rules, and synthesize them into a cohesive set.
The extraction process begins with a reasoning model that generates justifications for preferred outputs, from which explicit rules are derived and aggregated. These finalized rules are then assessed using language-model verifiers that evaluate how well each rule aligns with model outputs, providing a binary score that acts as an auxiliary reward during policy optimization.
Evaluations of the Llama-3-8B model trained with AUTORULE indicate significant performance improvements, including a notable increase in length-controlled win rates on AlpacaEval2.0 and enhanced second-turn performance on a held-out MT-Bench subset compared to a baseline model. The extracted rules align closely with user preferences, demonstrating their effectiveness in guiding model behavior.
A key benefit of AUTORULE is its capacity to reduce reward hacking, a prevalent issue in RLHF where models exploit weaknesses in learned reward systems. By utilizing rule-based rewards, AUTORULE establishes objective criteria that help ensure the model adheres to desired behaviors, thereby minimizing the risk of over-optimization.
Qualitative analyses further validate the framework's effectiveness, revealing that the extracted rules emphasize unique qualities valued across various datasets, such as conversational quality in UltraFeedback and adherence to instructions in MT-Bench.
AUTORULE represents a significant advancement in preference learning for language models, providing a scalable and automated method for deriving alignment rules from user feedback. The open-source code and extracted rules are available for further exploration, positioning this framework as a valuable tool for enhancing the performance and reliability of AI systems in alignment with human values. For additional information, the code can be accessed at [GitHub link].